
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
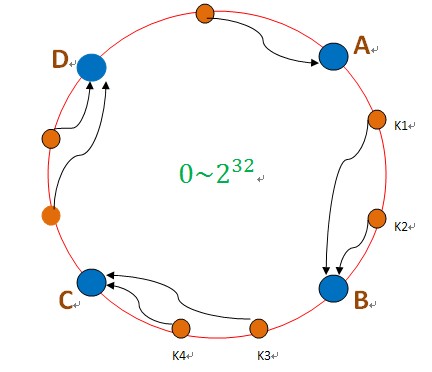
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
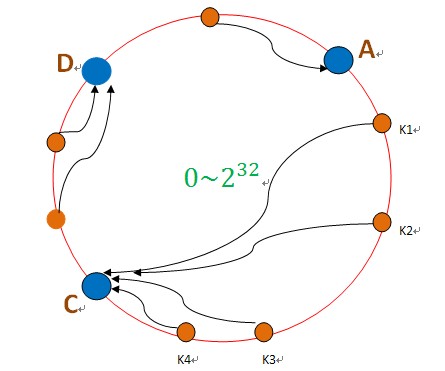
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
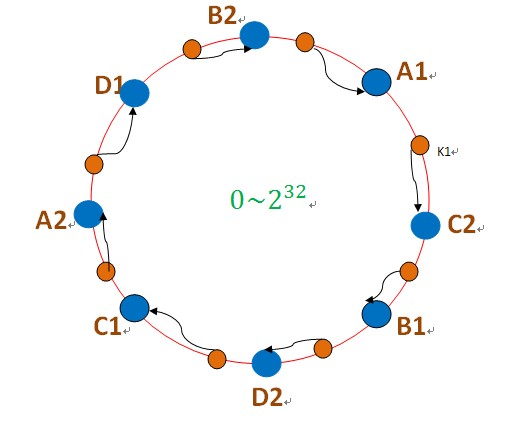
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
- public class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等
- private TreeMap<Long, S> nodes; // 虚拟节点
- private List<S> shards; // 真实机器节点
- private final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数
- public Shard(List<S> shards) {
- super();
- this.shards = shards;
- init();
- }
- private void init() { // 初始化一致性hash环
- nodes = new TreeMap<Long, S>();
- for (int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点
- final S shardInfo = shards.get(i);
- for (int n = 0; n < NODE_NUM; n++)
- // 一个真实机器节点关联NODE_NUM个虚拟节点
- nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
- }
- }
- public S getShardInfo(String key) {
- SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点
- if (tail.size() == 0) {
- return nodes.get(nodes.firstKey());
- }
- return tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息
- }
- /**
- * MurMurHash算法,是非加密HASH算法,性能很高,
- * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
- * 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
- * http://murmurhash.googlepages.com/
- */
- private Long hash(String key) {
- ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
- int seed = 0x1234ABCD;
- ByteOrder byteOrder = buf.order();
- buf.order(ByteOrder.LITTLE_ENDIAN);
- long m = 0xc6a4a7935bd1e995L;
- int r = 47;
- long h = seed ^ (buf.remaining() * m);
- long k;
- while (buf.remaining() >= 8) {
- k = buf.getLong();
- k *= m;
- k ^= k >>> r;
- k *= m;
- h ^= k;
- h *= m;
- }
- if (buf.remaining() > 0) {
- ByteBuffer finish = ByteBuffer.allocate(8).order(
- ByteOrder.LITTLE_ENDIAN);
- // for big-endian version, do this first:
- // finish.position(8-buf.remaining());
- finish.put(buf).rewind();
- h ^= finish.getLong();
- h *= m;
- }
- h ^= h >>> r;
- h *= m;
- h ^= h >>> r;
- buf.order(byteOrder);
- return h;
- }
- }



相关推荐
运行平台:VS 2019 一致性哈希算法演示项目,演示新增节点key分布情况;移除节点key分布情况! C#,C#,C#.......
ufire-springcloud-platform 学习微服-基于一致性哈希算法实现websocket分布式扩展的尝试。
如果没有找到,则取整个环的第个节点。测试结果测试代码是整理的,主体法没有变分布平均性测试:测试随机成的众多key是否会平均分布到各个结点上测试结果如下:最上是参
1、解决案:排序+List 2、解决案:遍历+List 1、最好情况是只有个服务器节点的Hash值于带路由结点的Hash值,其 2、最坏情况是所有服务器节点的H
随着虚拟节点的增加,数据量分配就比较平均了,但是并不是虚拟节点数量越多就越好,因为要考虑这些虚拟节点带来的性能开销以及算法的复杂性;
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;...
一致性哈希算法是分布式系统中常用的算法,为什么要用这个算法? 比如:一个分布式存储系统,要将数据存储到具体的节点(服务器)上, 在服务器数量不发生改变的情况下,如果采用普通的hash再对服务器总数量取模的...
另外,需要注意哈希表和双向链表的一致性维护。在put方法中,当新建节点或者更新节点时,都需要更新哈希表中的键值对,并将节点添加到链表头部;同样,在删除节点时,也需要从哈希表中删除对应的键值对。
一致性Hash算法,易于扩容;添加了 单元测试,使用Spring提供的RestTemplate调用RestFul风格的API接口;整合了 quartz 定时任务框架 ,并进行了封装,只需在构建完定时任务Job类后,在 application-quartz....
算法分类:排序算法(如冒泡排序、快速排序、归并排序),查找算法(如顺序查找、二分查找、哈希查找),图论算法(如Dijkstra最短路径算法、Floyd-Warshall算法、Prim最小生成树算法),动态规划,贪心算法,回溯法...
DataNode : 存储具体的数据,向 NameNode 主动发起心跳并采用请求响应的方式来实现上下线,便于 NameNode 发起挪动数据指令,实际挪动操作由 DataNode 自行完成;Client : 负责向 NameNode 请求 DataNode 相关信息并...
致性哈希算法在1997年由麻省理工学院提出(参见扩展阅读[1]),设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中...
如何保证事务的完整性和一致性? 5. SQL语言中的聚合函数有哪些?它们分别是什么作用? 数据结构题: 1. 什么是栈和队列?它们的应用场景是什么? 2. 什么是哈希表?如何实现一个哈希表? 3. 什么是二叉树?如何...
阿里的面试题集锦,内容包括红黑树、HashMap、ClassLoader、数据库、中间件、JVM、一致性哈希、网络等等
该存储库提供了常用分布式技术的演示,例如一致性哈希,分布式锁,分布式事务,领导者选举等。 技术 模块 地位 评论 一致性哈希 一致性哈希 完毕 分散式锁 分布式锁 正在做 分散式交易 分布式交易 完毕 共识算法 ...
一致性哈希算法? 1.1.2 Java语法糖 string的hash算法 hash冲突的解决办法:拉链法 foreach循环的原理 volatile关键字的底层实现原理 泛型类 泛型接口 泛型方法 反射 正则 捕获组和非捕获组 贪婪,勉强,独占模式 ...
环一致散列跳转一致哈希集合一致哈希磁悬浮一致性哈希 (第3.4节)粗略设计注意事项从与Karger等人成一直线的圆圈开始N个节点可以复制R次以改善分片分布。 复制的节点称为虚拟节点。 分片复制节点的散列在cicle上成...
与传统的一致性哈希算法相比,分布式数据具有更多的平衡。多丽丝建筑高性能Doris提供了高性能的KV访问,并具有低延迟和高吞吐量。 通常的数据访问时间少于4毫秒。可扩展性Doris旨在支持多达2000个以上节点的大规模...
+ Dubbo泛化调用的地址为一致性哈希负载均衡算法计算所得 + 解决了自定义协议在传输中导致的粘包、拆包问题 + 群聊批量ACK处理,避免因创建过多的超时计时器导致的压力过大 + 利用leaf-sno 【备注】 1、该资源内项目...
采用一致性哈希算法计算键所在的节点,每个节点都有一个唯一的ID用作标识,同时这个id也作为paxos的groupID,通过paxos在主备服务器之间进行同步数据。 KV存储的数据类型:int,字符串,列表,set,map。 客户端...